Author: Joonhee Lim
Team: UNIST RML
Date: 2022/02/04
참고 블로그(1): https://ropiens.tistory.com/85?category=965114
PPO 리뷰 : Proximal policy optimization algorithms
editor, Junyeob Baek Robotics Software Engineer /RL, Motion Planning and Control, SLAM, Vision - 해당 글은 기존 markdown형식으로 적어오던 리뷰 글을 블로그형식으로 다듬고 재구성한 글입니다 - original..
ropiens.tistory.com
참고 블로그(2): https://stella47.tistory.com/180
[작성중] PPO - Proximal Policy Optimization Algorithms 논문 리뷰 및 요약
요약 2. Background Policy Optimization Policy gradient method는 policy gradient 추정기를 계산하는 방법으로 작동한다. 아래의 경사 추정기 $\hat{g}$는 목적 함수 $L^{PG}$를 미분함으로써 얻는다. $$\hat{g..
stella47.tistory.com
0. Abstract
해당 논문에서는 환경과의 상호 작용을 통해 데이터를 샘플링하고 SGA를 사용하여 Surrogate Object Function을 최적화하는 강화학습을 위한 새로운 Policy Gradient 방법론을 제안하며 시뮬레이션 환경에서의 로봇 이동과 Atari Game에 PPO를 적용하여 기존 Policy Gradient 방식보다 우수함을 보여준다.
이전 Policy Gradient와의 차이점
- 미니 배치 업데이트를 이용함(이전의 방식은 데이터 샘플 하나당 한 번의 Gradient Update 수행)
- TRPO의 이점 중 일부를 가져왔지만 구현이 훨씬 간단하고 일반적으로 사용이 가능하다(TRPO는 제약이 있었음)
- 샘플 복잡성이 더 우수하다
1. Introduction
확장가능하고 효율적이며(데이터적으로) 하이퍼파라미터 조정없이 다양한 문제에서 강력한 방법 PPO 등장
DQN의 단점
- 많은 단순한 문제를 해결하지 못함
vanilla PG의 단점
- 데이터 효율성이 떨어짐
TRPO의 단점
- 매우 복잡하며 노이즈(드롭아웃 등) 또는 파라미터를 공유하는 아키텍쳐와는 호환되지 않음
이러한 문제점들을 해결하기 위해서 1차 최적화만을 사용하면서 좋은 데이터 효율과 성능을 달성하는 알고리즘을 개발하였다.
-> Policy 성능의 Pessimistic한 근사치를 형성하는 Clipped Probability ratios를 가진 새로운 Objective Function을 만듦
2. Background
2.1 Policy Gradient Methods
Policy Gradient 방법은 Policy Gradient의 근사기를 계산하고 SGA에 연결함으로써 작동한다.

여기서 πθ는 확률적 정책이고 Aˆ t는 Advantage Function의 근사기이다. 그리고 기댓값은 유한한 샘플 배치에 대한 실험적 평균이다.
π(at∣st): 정책 π를 따를 때, st에서 고른 액션이 at일 확률
Advantage Function이란?
RL에서는 "어떤 행동(Action)이 절대적으로 좋은가"보다는 "다른 행동보다 얼마나 좋은가"에 초점을 맞춘다. 이러한 개념을 Advantage Function이라고 표현한다.
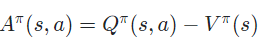
이 수식을 이해하기 위해서는 Value Function과 Action Value Function에 대해서 이해하고 있어야한다.
(1) On Policy Value Function
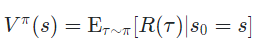
(2) On Policy Action-Value Function
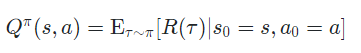
(3) Optimal Value Function
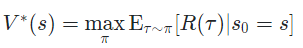
(4) Optimal Action-Value Function
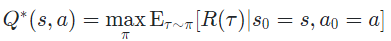
다음 수식을 본 후 Advantage Function을 이해해보면 s에서 a를 선택한 것이 안 한 것에 비해 얼마나 이득인지? 알 수 있게 해준다는 것을 확인할 수 있다.
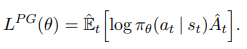
또한 g^은 해당 Objective Function을 미분함으로써 얻는다.
한계점: 너무 과도한 Policy 갱신을 유발한다.
2.2 Trust Region Methods
TRPO에서 Objective Function은 정책 업데이트 크기에 대한 제약을 두고 최대화시킨다.

여기서 θold가 update이전의 Policy parameter vector인데, 해당 문제는 Conjugate Gradient Algorithm을 사용해 근사적으로 해결한다.(Objective는 선형적으로 근사, Constraint는 이차식으로 근사)
-> 계산이 많고 엄청나게 복잡하다.. 이를 근사적으로 해결을 하긴 하였으나 추후 연구에서 분석하기에 최악이다
하지만 Schulman이 처음 TRPO를 정의하였을 때 특정 surrogate Objective가 Policy π의 성능을 보장하기 위한 Lower Bound를 형성한다는 개념을 따라 Constraint 방식이 아닌 Penalty 방식(Coefficient β를 이용)을 제시하였다.(제약 없이 최적화하겠다!)

그럼에도 고정된 β를 이용하여 다른 문제에서 or 학습과정 중 특성이 변하는 단일 문제 내에서 좋은 성과를 내기가 어렵기 때문에 Constraint 방식을 이용하였다.
이를 통하여 TRPO의 성능을 First-Order Algorithm으로 계산해내기 위해서는 고정된 Coefficient β를 선택하고 SGD를 이용한 Penalized Objective를 최적화하는 것만으로는 충분치 않다는 것을 보여준다.
KL-Divergence란?

KLD란 P분포와 Q분포가 얼마나 다른지 측정하는 방법이다.
KLD값이 낮을수록 두 분포가 유사하다라고 해석하며, 이는 Entropy값이 낮을수록 랜덤성이 낮다고 해석하는 것과 유사하다.
3. Clipped Surrogate Objective
Probability Ratio를 다음과 같이 정의한다.

그리고 이를 기존의 "Surrogate" Objective Function(위에 있음요)에 적용하면 다음과 같이 표현할 수 있다.
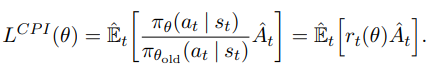
CPI: Conservative Policy Iteration
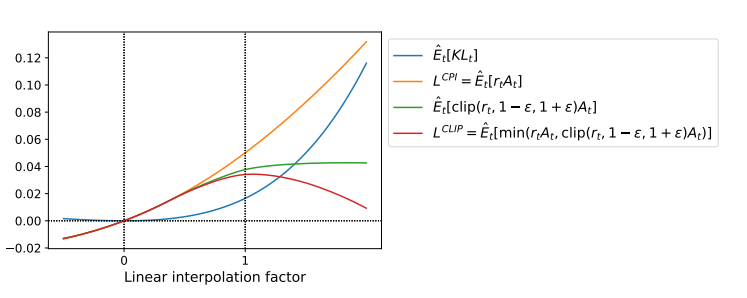
Constraint없이 위 Objective를 최대화하게 되면 Policy Update가 과도하게 많이 진행될 수 있다.
-> Probability Ratio를 1에서 멀어지게 하는 정책의 변화에 대해 페널티를 부여하면 어떨까?

첫 항은 기존의 Objective이고 두번째 항은 Clipped Probability Ratio를 적용한 항이다.
이 둘을 비교해 더 작은 값을 취함으로써 Lower Bound 형성하는데 의미가 있다.

A>0이고 r>0이면 위 수식에 따라 L CLIP이 계속 증가한다.(다만 너무 증가하지 않도록 Clip한다)
A<0이고 r>0이면 위 수식에 따라 L CLIP이 계속 감소한다.(다만 너무 커지지 않도록 Clip한다(?))
4. Adaptive KL Penalty Coefficient
Clipped Surrogate Objective의 대안으로 또는 그 외 사용할 수 있는 접근법은 KL Divergence에 대한 페널티를 사용하고, 매 정책 업데이트마다 KL Divergence의 목표값을 달성할 수 있도록 페널티 계수를 조정하는 것이다.
-> 앞선 실험에서 보인 Clipped Surrogate Objective보다 좋은 성능을 내진 못하지만 충분히 중요하기에 설명하였다고 한다.

논문에 따르면 β는 드물게 업데이트된다. 또한 1.5와 2는 경험적으로 얻어낸 파라미터이며 그다지 민감하지 않다.
β의 초기값은 알고리즘이 빠르게 초정하기 때문에 실제로는 그렇게 중요하지 않다.
5. Algorithm
앞서 보인 Surrogate Loss는 기존과 Policy Gradient에 약간의 변화를 주어 계산하고 미분할 수 있다.
자동 미분을 이용한 구현에서는, Surogate Loss는 Lpg대신에 L CLIP 또는 L KLPEN으로 구성한 뒤 SGA의 단계를 수행한다.
분산이 감소된 Advantage Function 근사기를 계산하는 과정에는 Value Function V(s)를 사용한다.
PPO에서는 Policy와 Value function의 Parameter 공유가 되는 Neural Network를 사용하는데 이를 위해 Loss Function이 Policy Surrogate와 Value Function Error와 관련된 term을 결합하여 설계된다. 이 때 학습의 충분한 Explaration을 보장하기 위해 Entropy 항을 추가하는 것으로 보완된다.

L CLIP: 앞서 설명한 Clipped Surrogate Objective
L VF: Value Function의 Squared-error Loss (Value - Target Value)^2
S: 엔트로피 항
c1, c2: 각각의 Loss의 비중을 결정하는 파라미터
이는 RNN에서 알맞게 사용되고 있는 방법으로, T timestep만큼 미리 sample을 모아 업데이트하는 방식이다.
T만큼의 trajectory segment를 sample로써 하나의 미니배치로 사용하는 것이다.
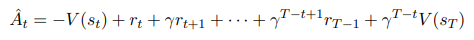
이 개념을 일반화하면 Truncated version of generalized advantage estimation으로 탄생하게 된다.
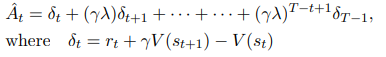
PPO는 아래와 같이 매 iteration마다 N개의 Actor가 T timestep만큼의 데이터를 모아 업데이트하는 방식이다.
즉 NT개의 데이터를 이용해 Surrogate Loss를 형성하고, minibatch SGD를 적용해 이를 업데이트한다.

6. Experiments
앞서 말한 3가지의 Objective를 평가하는 시간.
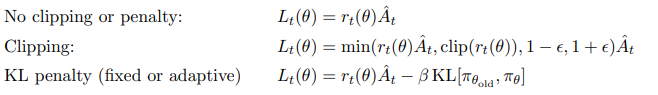
결과는 다음과 같다.
-> 그리하여 L Clipped를 사용하는 것 같다
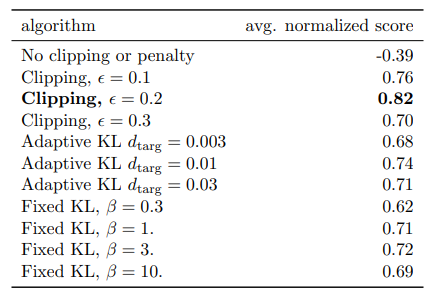
다른 알고리즘과의 비교는 다음과 같은 결과를 냈다.

7. Conclusion
PPO는 안정적이고 TRPO보다 구현이 쉬우며 TRPO의 장점을 가지고 있다. 또한 파라미터를 공유하는 다양한 상황에 적용이 가능하며 더 좋은 성능을 가진다.
사진 출처: 논문 원문



