Author: Kangchan Roh
Date: 2022/08/01
▣ 머리말
이번 포스팅은 DQN을 공부해보았고 더욱 알고 싶어서 코드로 접해보고 싶지만 막연함에 접해보지 못한 분들께 좋은 포스팅일 것 같습니다. DQN의 핵심 알고리즘이(Q-learning : (TD-target, value-based, e-greedy), Q-Network, Experience Replay... 음 요 정도..?) 코드에 어떤 부분에 해당하는 지 대응해보고 코드를 실행해보며 DQN을 더 느낌 와닿게 리마인딩해보는 의미있는 시간이 됐으면 하는 바람입니다. 저도 이번에 처음으로 강화학습 코드를 제작해보면서 DQN을 더 풍부하게 막 방금 느껴보고 기록하는 중이에요. 코드는 아래 환경 설명 부분에 첨부되어 있습니다. 처음이라 저도 왕초보인 점 알아주세요ㅋ
▣ DQN이 뭐더라?
DQN 슥 다시 되짚어보고 갈까요~?
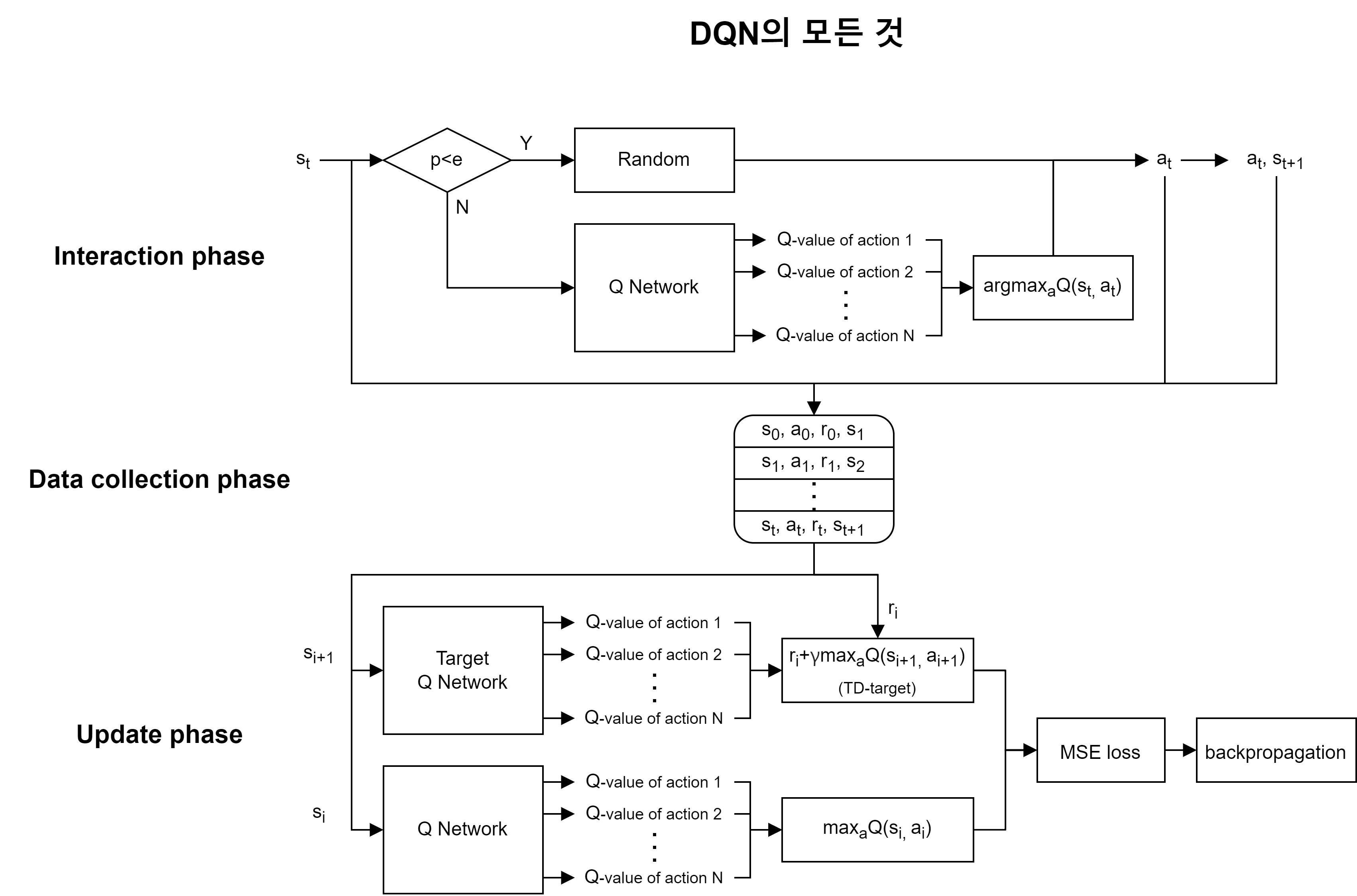
위 그림은 DQN의 모든 것을 담은 다이어그램입니다.
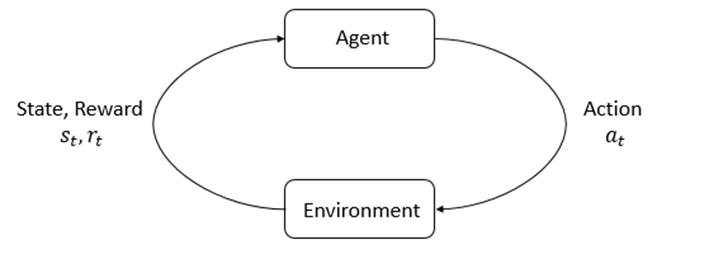
강화학습은 기본적으로 아래 그림과 같이 agent와 environment가 action과 state, reward를 주고 받으며(상호작용) reward가 큰 action을 학습하는 것이 목표라 했습니다. 그 과정이 policy 기반이면 policy-based, Q나 V같은 값을 기반으로하면 value-based입니다. DQN은 value-based의 대표적인 알고리즘인 Q-learning을 기반으로하고 DQN이라는 제목에 걸맞게 Q-Network가 각 action들에 대해 추론한 Q-value들을 산출합니다. 그리고 Q-value에 대해 action의 argmax 연산을 하여 max Q-value의 action을 취하는 greedy action을 합니다. 그렇게 환경과 상호작용한 데이터를 버퍼에 저장을 하고 random하게 일정크기 데이터를 골라 학습하여 데이터 간의 상관관계를 줄입니다(Experience Replay). 학습에 사용되는 object function은 Target Q Network의 TD-target과 main network의 max Q-value간의 MSE loss를 사용합니다.
▣ DQN 코드리뷰
기본적인 DQN의 내용을 되짚어보았고 DQN을 공부를 하신 분들이라면 다 이해했을 겁니다.
이제 이 내용들이 코드에 어떤 부분과 대응되는 지 살펴보고 실행도 해봅시다!
Gym의 Car Racing 환경을 사용해볼 거예요!
◆ Car Racing gym 환경 (학습코드파일 첨부)
이리저리 돌아다니면서 적당한 베이스코드 찾고 Car Racing 환경에 맞게 디버깅한 학습코드에요.
살펴보시면서 부디 좋은 공부자료가 되길 바랍니다..
- DQN_CarRacing
└── DQN_example
├── dqn.py
├── main.py
└── __pycache__
├── dqn.cpython-37.pyc
└── dqn.cpython-39.pyc
- dqn.py : 강화학습 agent 클래스, Q-Network 모델
- main.py : gym의 car-racing환경과 상호작용하게 해주는 실행문
구글링해서 적당한 DQN코드를 찾았다면 우리가 적용할 환경의 state의 shape와 action의 space를 파악해서 입맛에 맞게 활용해봅시다.
저희가 살펴볼 환경은 Gym에서 제공하는 Car Racing입니다!
Car Racing 환경에서 입력으로 들어갈 action의 space와 출력되는 state의 shape는 아래와 같습니다.
이 점들을 잘 기억하고 코드리뷰를 시작해봅시다.
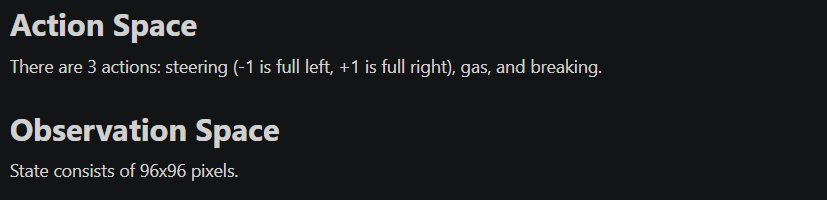
- Action Space : Box([-1. 0. 0.], 1.0, (3,), float32)
Car Racing 환경의 action space 도메인은 continuous합니다. 알다시피 DQN의 output action은 discrete합니다. 그래서 환경의 action space 도메인 중에 값을 적절히 골라서 discrete한 action space로도 기존 환경의 action space를 잘 대변할 수 있어야 합니다. 저는 다음과 같이 action space를 재구성하여 Q-Network의 output을 12개 action의 Q-value로 구성했습니다.- action[0] ← 3개의 steering wheel 상태 (-1 : 왼쪽, 0 : 직진, +1 : 오른쪽)
- action[1] ← 2개의 gas(악셀) 상태 (0 : 악셀X, 1 : 풀악셀)
- action[2] ← 2개의 break 상태 (0 : 브레이크X, 0.2 : 20% 브레이크)
| action_index | action[3] |
| 0 | [-1, 0, 0] |
| 1 | [-1, 0, 0.2] |
| 2 | [-1, 1, 0] |
| 3 | [-1, 1, 0.2] |
| 4 | [0, 0, 0] |
| 5 | [0, 0, 0.2] |
| 6 | [0, 1, 0] |
| 7 | [0, 1, 0.2] |
| 8 | [1, 0, 0] |
| 9 | [1, 0, 0.2] |
| 10 | [1, 1, 0] |
| 11 | [1, 1, 0.2] |
- Observation Shape : (96, 96, 3)
Gym의 Car Racing 환경은 (96 x 96 x 3) 형태의 observation(state라고 간주)를 출력합니다. 여기서 3은 RGB값을 의미하는 것이 아니라 (96 x 96) x 3 으로 96 x 96 이미지 연속 3장을 의미합니다.
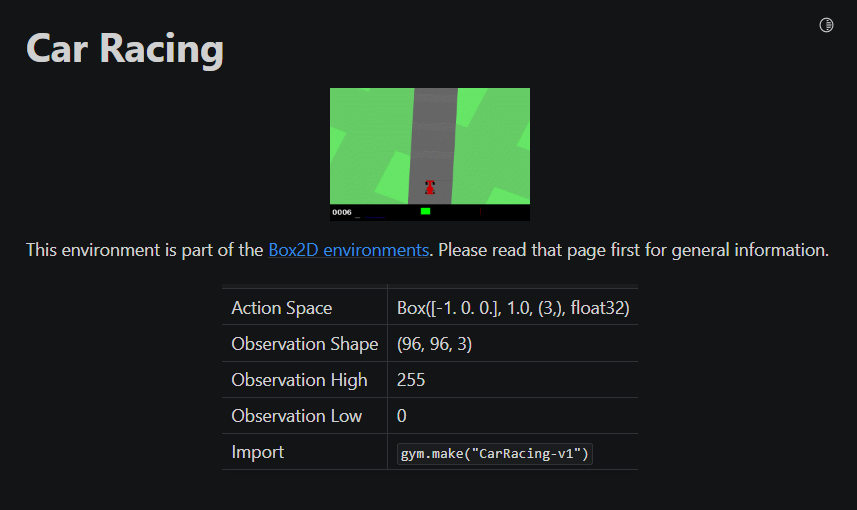
참고: https://www.gymlibrary.ml/environments/box2d/car_racing/
Car Racing - Gym Documentation
Previous Bipedal Walker
www.gymlibrary.ml
◆ 코드리뷰
업로드한 첨부파일을 참고하면서 봐주세요!
■ Agent
- main문에서 Agent 선언

- Agent 클래스
에이전트가 선언될 때 필요한 여러 파라미터들을 받는다. DQN_CNN 클래스로 Q-Network들이 생성되었고 메서드 store_transition(), choose_action(), learn() 로 에이전트가 수행해야 할 것들을 구현해놓았다.
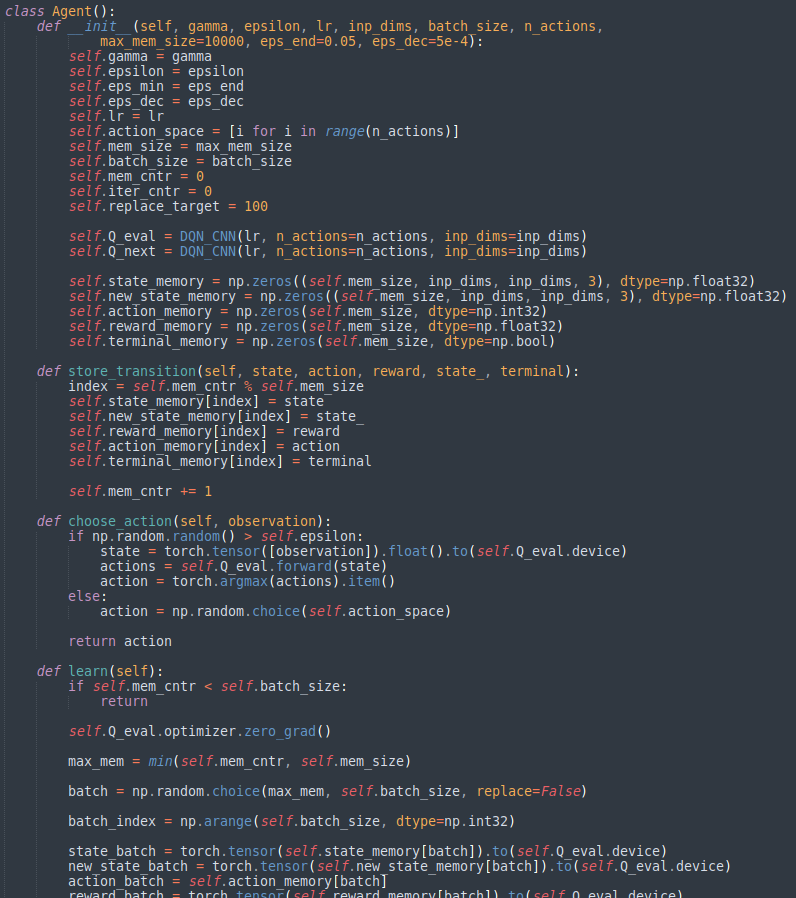
■ Value-Based, Q-Network
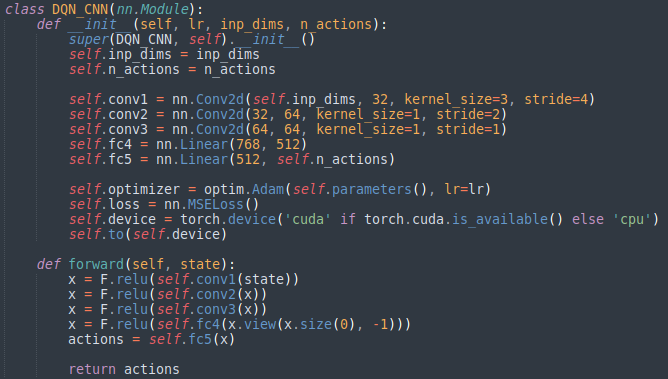
Q-Network 클래스이다. 생성된 객체는 lr, inp_dims, n_actions 파라미터를 가진다. lr은 learning rate, inp_dims는 input의 차원 그리고 n_actions는 action의 개수이다.(그러면 이 환경에서는 inp_dims = 96, n_actions = 12가 되야겠죠?) 이 클래스로 선언된 객체(Q-Network)가 state를 받아서 메서드 forward를 행하면 n_actions 수 만큼의 Q-value를 return한다.
■ e-greedy
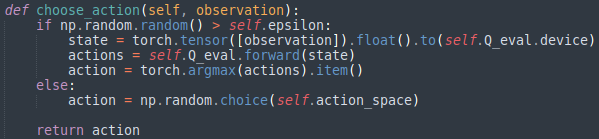
위의 Agent 클래스의 choose_action() 메서드이다. 매우 간단하게 e-greedy알고리즘을 구현해놓았다. numpy 랜덤함수의 출력값이 epsilon 값보다 크면 DQN_CNN클래스로 생성된 객체인 Q-Network에 state를 forward하여 return받은 actions를 argmax연산을 통해 actions의 index를 return한다. 반면 그 외(else: 랜덤함수의 출력값이 epsilon 값보다 작거나 같으면)에는 랜덤한 index를 return한다.
■ Experience Replay, TD-target
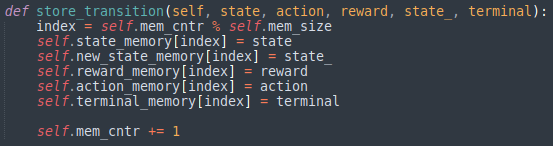
Agent가 생성될 때 받은 메모리 사이즈 파라미터 값을 활용하여 state가 transition 될 때 정보들을 버퍼에 state에 대해 인덱싱하며 저장한다.
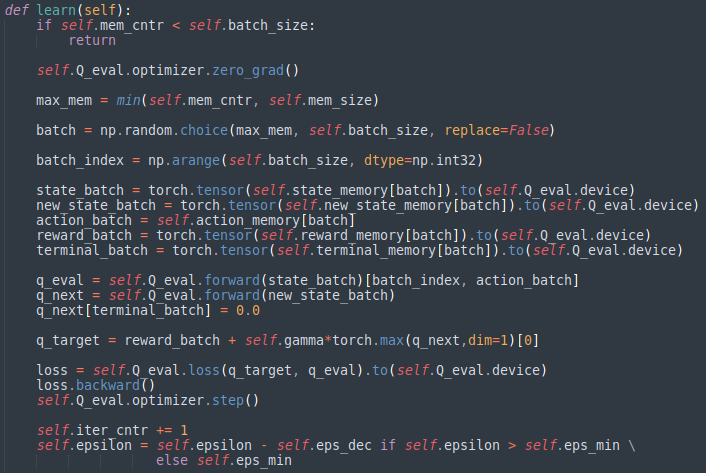
버퍼 속 experience들이 일정 용량이 될 때 random하게 experience들을 꺼내어 Q-Network를 학습한다. 그리고 Target Q-Network에서 다음 state를 forward하여 Q-value를 얻어 TD-target을 만들고 Main Q-Network에 현재 state를 forward한 Q-value를 얻어 이 둘에 대해 MSE loss를 계산하고 optimize한다. 그리고 학습 초기에는 epsilon을 1로 두고exploration의 비율을 크게하고 학습을 할 수록 epsilon을 점점 줄이며 exploration을 줄여나간다.
■ main문 살펴보기
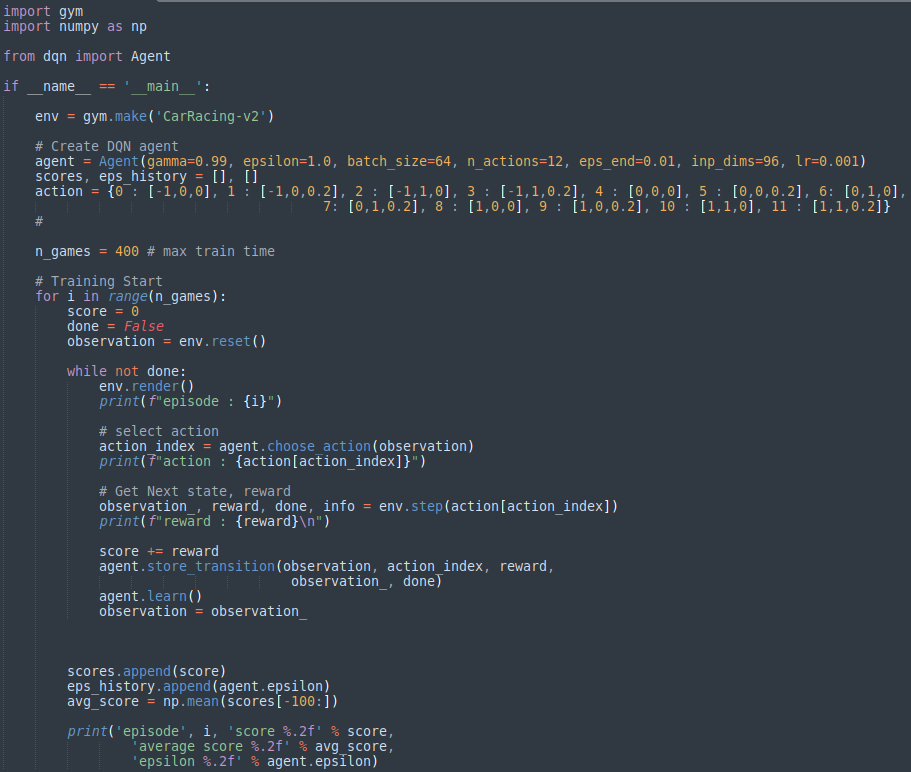
- 환경을 불러오고 초기화한다
while not done 2~4: - 환경에 대한 observation을 agent에 input하고 output으로 action을 얻는다.
- Agent가 output한 action을 환경에 step하고 next observation, reward, done, info를 받고 버퍼에 transition data를 저장한다.
- learn한다.
▣ 환경세팅 및 실습코드 실행
■ 필자 시스템 환경 구성
- Ubuntu 20.04
- CUDA 11.3
- PyTorch 1.12.0
■ Dependencies
- Gym
- Box2D
- PyTorch
윈도우에서도 가능합니다. CUDA 없어도 됩니다.
◆ Anaconda 설치
참고: https://ieworld.tistory.com/12
[우분투/Ubuntu 20.04] 우분투에 아나콘다 설치 / Install Anaconda on Ubuntu
파이썬 IDLE는 설치했지만 이것만 쓸 수는 없기에 대부분의 파이썬 유저들이 사용하는 아나콘다라는 툴을 설치하자 먼저 아나콘다 공식 홈페이지에 들어가서 Individual Edition을 다운받아준다 - www.
ieworld.tistory.com
◆ Anaconda 가상환경 만들기
$ conda create -n <원하는 가상환경 이름> python=<원하는 파이썬 버전> #가상환경 만들기
$ conda acticate <제작한 가상환경 이름> #가상환경 활성화저는 carracing이름의 가상환경을 만들었고 파이썬 버전은 3.7.11을 이용했습니다.
딱히 이유는 없고 요새 제가 하는게 3.7.11에서 해야해서.. 다른 버전 해도 될 걸요? (해보셈ㅋ)
◆ 의존 패키지 설치
- Gym
$ pip install gym- Box2D
$ pip install gym[box2d]- PyTorch
저는 Ubuntu에 CUDA를 사용하고 있습니다. 저랑 동일한 환경이신 분들은 이렇게..
$ conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorchCUDA가 없으시면 아마 요러케 하시면 될 거예요. (probably..?)
$ conda install -c pytorch pytorch
참고: https://pytorch.org/get-started/locally/
PyTorch
An open source machine learning framework that accelerates the path from research prototyping to production deployment.
pytorch.org
◆ 코드 실행
- DQN_CarRacing
└── DQN_example
├── dqn.py
├── main.py
└── __pycache__
├── dqn.cpython-37.pyc
└── dqn.cpython-39.pyc
$ cd ~/DQN_CarRacing/DQN_example
$ python main.py■ 실행 화면
■ (번외) Car Racing 직접 키보드로 게임하고 싶음?
아나콘다 환경 폴더 들어가서 gym라이브러리 들어가서 아래 경로 들어가시고 car_racing.py 실행하면 직접 게임할 수 있습니다.
$ python gym/envs/box2d/car_racing.py▣ 꼬리말
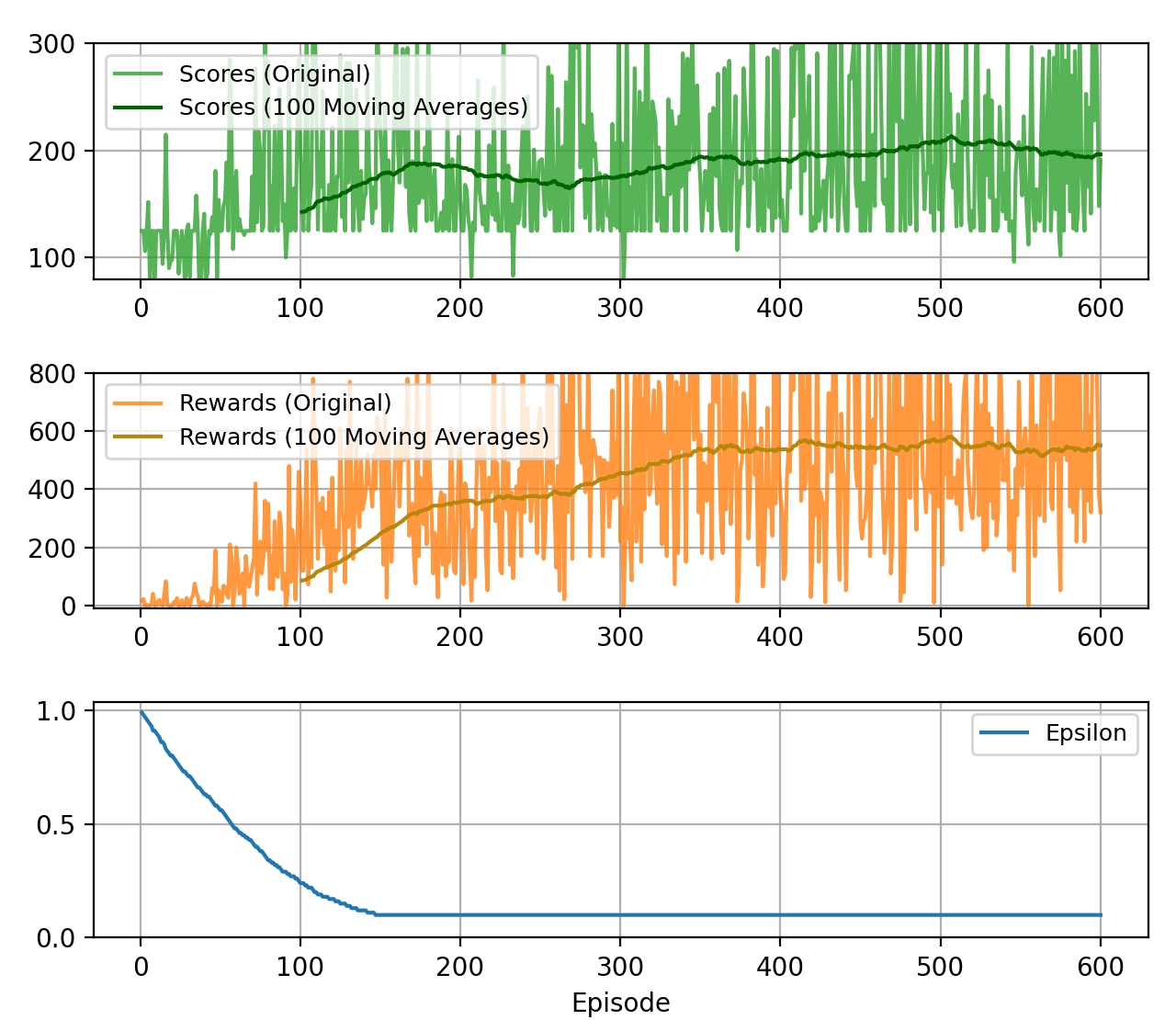
400-500 episode는 가야한다고 합니다. 위 영상은 0 episode.
추후에 학습 저장, 불러오기 기능 넣어서 학습해서 에피소드 별로 업데이트 하겠습니다.
나중엔 DDPG, PPO, SAC등 여러 알고리즘으로 뵈어요.
감사합니다.
일단 끝.
Date: 2022/08/08
학습을 해보았는데 잘 안된다. 필요 없어보이는 액션을 줄여보기도 하고 step이 아닌 episode가 진행됨에 따라 epsilon을 줄여보기도하였다. 근데 내 에이전트 게임 개 못한다.
그래서 DQN의 한계인가하고 넘어 가려했는데 구글링 해보니 DQN으로 꽤 괜찮게 게임을 플레이하는 에이전트를 볼 수 있었다.
https://github.com/andywu0913/OpenAI-GYM-CarRacing-DQN
GitHub - andywu0913/OpenAI-GYM-CarRacing-DQN: Train a DQN Agent to play CarRacing 2d using TensorFlow and Keras.
Train a DQN Agent to play CarRacing 2d using TensorFlow and Keras. - GitHub - andywu0913/OpenAI-GYM-CarRacing-DQN: Train a DQN Agent to play CarRacing 2d using TensorFlow and Keras.
github.com
그래서 내 코드랑 이 분 코드랑 비교하면서 차이점이 무엇인 지 파악중이다. 차이점이 몇 개 있었다.
일단 레이어 구성이 달랐고 image를 state로 넣기 전에 흑백으로 바꿔주는 전처리 작업, frame skipping을 코드로 구현, 괜찮은 액션에는 수행할 수록 보너스리워드를 주는 아이디어, 좀 구린 액션이 지속되면 그 수치를 카운트해서 일정 이상이 되거나 게임 점수(score)가 음수가 되면 바로 그 에피소드를 종료시켜버리는 아이디어가 있었다. 이를 제 코드에 적용시키려고 해봤는데 에러가 떠서 디버깅 중..
'Reinforcement Learning' 카테고리의 다른 글
| [RL] Model : 모델이란(생각보다 간단하게) (2) | 2022.11.30 |
|---|---|
| [RL] Linear Inverse Reinforcement Learning에 대한 글 (0) | 2022.08.24 |
| [RL] Imitation Learning(모방 학습)에 대한 설명 및 정리 (0) | 2022.08.23 |
| [RL] End-to-End Autonomous Driving in Simulation using Reinforcement Learning: PPO 활용 (0) | 2022.01.26 |
| [RL] End-to-End Autonomous Driving in Simulation using Reinforcement Learning: DQN 활용 (0) | 2022.01.17 |

