728x90
Author: KangchanRoh
Team: Reinforcement Learning Team @ CAI Lab
Date: 2022/11/30
1. 학습 진행
(1) 로봇 및 카메라
- OMO-R1
- 카메라 : Intel RealSense D435

(2) 학습 모델 파라미터 설정 (config 파일)
- 커스텀 파라미터
- 로봇 반경 : 0.47m
- 로봇 최대 속도 : 1.2m/s
- 카메라 화각 : 86도
- 학습할 스텝 수 : 20e7
- 그 외 파라미터
- 속도 $v$, 각속도 $\omega$로 주행하는 unicycle 타입 로봇에 맞게 저자들이 제시한 디폴트 파라미터로 설정.
- 학습 횟수
- 2000만 Step만큼 학습 진행
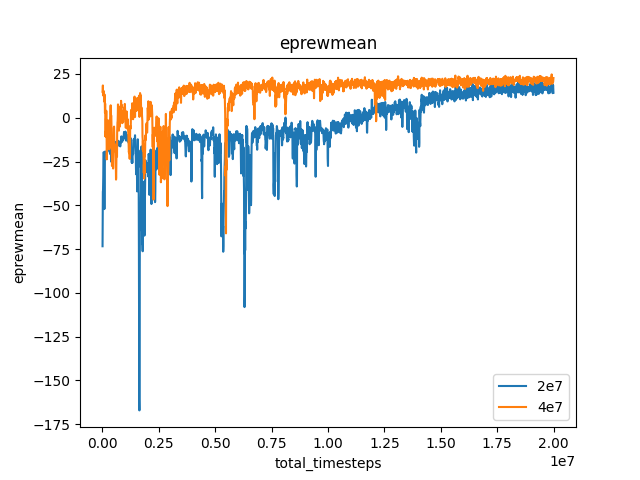
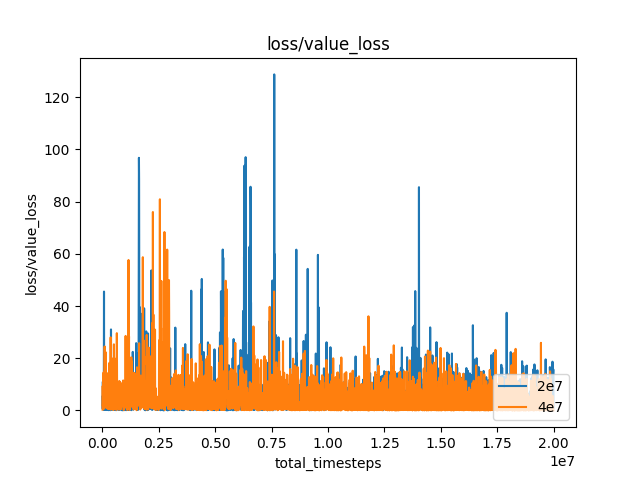
- 1회차 학습 (파란색 그래프)
- 2회차 학습 (주황색 그래프)
- 1회차 학습 모델을 pre-train으로 가정하여 학습 진행
2. 학습 결과
(1) 에피소드 별 평균 리워드 그래프
(2) Critic Loss 그래프
(3) 주행 성공률
| 성공률 | 89% |
| 충돌률 | 11% |
| 시간초과율 | 0% |
- 성공률 : 로봇이 목표지점(goal)까지 사람들과 충돌하지 않고 도달한 비율.
- 충돌룰 : 로봇이 목표지점(goal)으로 주행하는 과정에 사람과 충돌하여 주행을 실패한 비율.
- 시간초과율 : 로봇이 일정 시간 내에 목표지점(goal)에 도달하지 못한 비율.test_4000만 step
- 테스트 영상 2배속 (성공)
- 테스트 영상 2배속 (충돌)
- 정지하는 action 추가
- (큰)회전에 대한 패널티 추가 → 보상 함수 보완 필요
(4) 결과 분석
- 전체적으로 시뮬레이션을 봤을 때 상당히 합리적으로 잘 움직임.
- 충돌 원인 분석
- 카메라에서 비롯된 화각의 한계
- 로봇이 사람들로 하여금 비키게끔 강요하는 것을 방지하기 위해 학습 및 테스트 환경에서 사람은 처음 경로를 바꾸지 않게끔 설정하였음 → 실제 환경에서는 사람들 또한 충돌 회피를 하는 점을 고려하면, 하드웨어를 보강하여 connercase들을 학습하기만 하면 실제로 활용하기에도 충분한 성능이라고 평가 되어짐.
반응형
'인공지능 환경세팅' 카테고리의 다른 글
| YOLO + Object Tracking (0) | 2022.11.30 |
|---|---|
| [환경 세팅] Ubuntu 20.04에 CUDA 11.3 cuDNN 8.2.1 설치하기 (1) | 2022.07.26 |

