728x90
Author: Jihwa Lee
Team: Autonomous Driving Team @ CAI Lab
Date: 2023/01/25
출처: https://arxiv.org/pdf/2210.00379v1.pdf
3. Neural Radiance Field ( NeRF )
아래 많은 분야의 모델들 중 관심있는 분야인 Fundamentals와 Pose Estimation 부분만 살펴보겠다.

3.1 Fundamentals
- Mip-NeRF (March 2021)
- 기본 모델에 대비하여 저해상도에서 좋은 결과를 나타냈다.
- standard NeRF의 ray tracing 대신 *cone tracing을 이용
( *cone tracing: 두께가 없는 광선을 두꺼운 관선으로 대체하는 광선 추적 알고리즘) - 이를 위해 *Integrated Positional Encoding을 사용하였다.
(*Integrated Positional Encoding: positional encoding의 일반화로, 공간의 single point가 아니라 공간 영역을 feature화) - cone은 *multivariate Gaussian에 의해 approximated
(*multivariate Gaussian(다변량 가우시안 분포): 일차원의 정규분포를 다차원으로 확장시킨 개념)
- Ref-NeRF (December 2021)
- Base Model: Mip-NeRF
- model의 reflective surface을 표현하는 성능을 향상시켰다.
- local normal vector에 대한 viewing direction에 따른 reflection, NeRF radiance를 parameterized
- parameterized하기 위해 density MLP를 directionless MLP로 변경하였다.
- 그래서 기존의 output이었던 density와 input feature vector뿐만 아니라 diffuse color와 specular tint, roughness, surface normal을 도출한다.
- roughness로 부터 parameterized 한 spherical Gaussian으로 부터 vector를 sample로 뽑아 *sperical harmonics를 이용하여 방향 도함수를 parameterized 했다.
(*special harmonics: 구면조화 함수 -> 자세한 설명은 더보기 )더보기구면조화 함수란 구면에 존재하는 주기 함수이다.
Sphere 상에 존재하므로 2$\pi$를 주기로 주기가 정확히 일치해야한다.
Spherical Harmonics는 구면좌표계에서 라플라스 방정식을 풀었을 때 얻을 수 있다.
자세한 설명은 위 글의 출처인 https://woochan-autobiography.tistory.com/954 를 참고하면 좋을 듯하다. - 이를 통해 특히 reflective surface에서 좋은 결과를 얻을 수 있었고 정확한 modeling의 specular reflections과 highlights를 얻을 수 있었다.
- 여기서 사용한 데이터 셋은 Shiny Blender dataset, original NeRF dataset, Real Captured Scenes이다.
- RegNeRF (December 2021)
- NeRF의 training 과정의 문제점을 sparse input view로 해결하고자 하였다.
- 다른 모델과 다르게 이 모델은 NeRF volume rendering을 위한 prior conditioning을 pretrained network를 통한 image feature를 이용해 해결하였다.
- 사용한 데이터 셋은 DTU, LLFF를 이용하여 PixelNeRF와 SRF, MVSNeR와 비교하였다.
- 다른 모델들은 DTU에 대해 pre-train과 장면마다 fine-tuning이 필요하지만, RegNeRF는 pretraining이 필요없다.
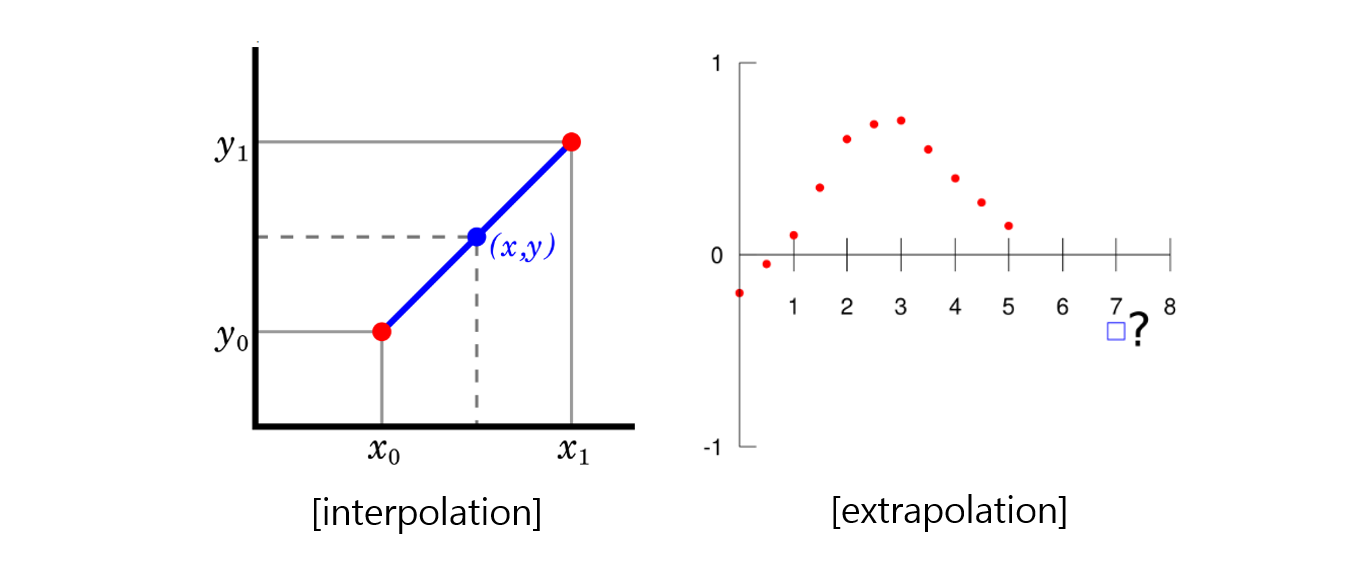
- RapNeRF (May 2022)
- original NeRF는 *interpolation에 적합한 모델이었다면 RapNeRF는 *extrapolation에 적합한 모델로 발전시켰다.
(*interpolation: 범위 안에 있는 값을 예측하는 것, *extrapolation : 범위 밖에 있는 값을 예측하는 것) - Random Ray Casting(RRC)과 Ray Atlas(RA)를 개발하여 extrapolation에 대해 학습하였으며 이것은 다른 NeRF모델에서도 ray를 training하는 과정에서 augment하는 기법으로 적용 가능하다고 한다.
- augment해서 학습한 결과 synthesis quality가 더욱 좋아졌다고 필자는 말하였다.
- 데이터 셋은 Synthetic NeRF dataset, their own MobileObject dataset을 사용하였다.
- original NeRF는 *interpolation에 적합한 모델이었다면 RapNeRF는 *extrapolation에 적합한 모델로 발전시켰다.
3.1.1 Deformation Fields
- Nerfies (November 2020)
- 움직이는 사물(사람)이 있는 환경에서 아주 좋은 결과를 보였다.
- 이는 additional MLP를 이용하였는데, 이를 이용하여 elastic regularization, 배경 regularization, coarse-to-fine deformation regularization을 더하였다.
- 이 모델과 경쟁 모델로는 NerFace와 Face2Face라는 모델이 있다.
- HyperNeRF (June 2021)
- 사람이 입을 벌리거나 바나나를 까는 등의 예시에서 물리적인 연결(topological)이 변화하는 사례에 대해 좋은 결과를 보였다.
- 추가적인 slicing MLP를 추가하여 ambient space coordinate를 이용해 3D representation을 어떻게 return할지에 대한 연산을 추가하였다.
- CoNeRF (December 2021)
- HyperNeRF를 개량한 모델이다.
- 이 모델은 슬라이더로 사진을 쉽게 편집할 수 있다는 점이 특징이다.
- 슬라이더를 통해 사람의 표정을 조절하고 원하는 example dataset을 만들 수 있다.
3.1.2 Depth Supervision and Point Cloud Methods
LiDAR나 SfM을 통해 얻은 point clouds를 이용하여 depth를 학습하는 것은 (1) 빠르게 수렴하고, (2) 높은 퀄리티를 자랑하며 (3) 적은 양의 시야를 필요로한다는 장점이 있다.
- Depth-Supervised NeRF (July 2021)
- 적은 양의 데이터로 빠르고 좋은 품질로 multi-view synthesis하는 모델
- Point cloud로 depth를 학습시킨 모델이다.
- volume rendering과 photometric loss를 통한 color supervision 뿐만 아니라 COLMAP을 이용한 training image로 부터 point cloud를 추출하여 모델을 실행할 수 있다.
- 사용한 데이터셋은 DTU, NeRF dataset, RedWood-3dscan dataset이고 비교 모델은 baseline NeRF와 pixelNeRF, MVSNeRF를 사용하였다.
- Dense depth priors for neural radieance fields from sparse input views (April 2021)
- 이 연구에서는 COLMAP을 이용하여 point cloud를 추출하여 학습하였다.
- Depth loss에 predict depth와 uncertainty를 더하여 사용하였다.
- ScanNet의 RGB-D 데이터와 Matterport3D를 이용해 depth에 Gaussian noise를 더해 학습하였다.
- DS-NeRF와 baseline NeRF, NerfingMVS와 성능을 비교하였다.
- NerfingMVS (September 2021)
- depth reconstruction에 초점을 맞춰 그들의 NeRF model에서 multi-view 이미지를 사용하였다.
- COLMAP을 사용하여 sparse depth prior을 point cloud 형태에서 추출하였다.
- sparse depth prior을 pretrain된 monocular depth network에 넣고 depth map prior을 추출한다.
- depth map prior 중 적절한 depth 값을 가진 sampling points만 volume sampling을 학습하는데 사용한다.
- volume rendering을 하는 동안 ray는 같은 크기의 N개의 구간으로 나뉘어진다. (depth prior을 이용하여 ray bound를 clamp한다.)
- 사용한 데이터셋은 ScanNet이다.
- PointNeRF (January 2022)
- feature point cloud를 volume rendering을 하기 위한 중요한 step으로 사용하였다.
- Pretrained 3D CNN이 surface probability $\gamma$와 depth를 generate 하는데 사용되고 dense point cloud를 생성하는데 사용된다.
- Pretrained 2D CNN은 training view로부터 image feature를 추출하는데 사용된다.
- 주어진 input position과 view-direction은 PointNet을 통해 local density와 색상으로 추출되어 volume rendering에 사용된다.
- point cloud feature를 사용하는 것은 빈공간을 생략하는 것을 통해 속도면에서 baseline NeRF를 넘어설 수 있었다.
- PixelNeRF와 MVSNeRF, IBRNet과 성능을 비교하였고, DTU dataset을 pruning하여 사용하였다.
3.2 Improvements to Training and Inference Speed -> pass
3.3 Few Shot/Sparse Training View NeRF -> pass
3.4 (Latent) Conditional NeRF -> pass
3.5 Unbound Scene and Scene Composition -> pass
3.6 Pose Estimation
- iMAP (March 2021)
- 원저자는 첫 NeRF-based dense online SLAM 모델이라고 소개하였다.
- 이 모델은 카메라 pose와 implict scene representation을 계속되는 online learning을 통해 유기적으로 최적화한다.
- 이 모델은 tracking과 mapping, two-step 으로 구성되어있다.
- iMAP은 pose tracking 속도가 mapping 과정에서 사용되는 tracking step보다 더욱 빠르도록 하는 것에 성공하였다.
- NICE-SLAM (December 2021)
- iMAP을 기반으로 keyframe selection과 NeRF architecture의 성능을 향상시켰다.
- iMAP에 비해 pose estimation error가 적고 scene reconstruction의 성능은 높였다.
- 이뿐만 아니라 연산량도 대폭 줄여 tracking time과 mapping time을 줄였다.
3.7 Adjacent Methods -> Pass
3.8 Applications 부분은 다음 게시물로 알아보도록 하겠다!
반응형


