Author: Dahyeon Lee
Date: 2022/08/25
논문: Masked Autoencoders Are Scalabel Vision Learners
https://arxiv.org/abs/2111.06377
[Summary]
데이터의 일부를 지우고, 그 부분을 예측하기 위해 학습하는 개념을 통해 NLP에서 좋은 성과를 보였다고 한다.
본 연구는 이러한 masked autoencoding (self-supervised pre-training) 개념을 CV에 적용해보았다고 볼 수 있다.
이 때 language와 image 차이로 나타나는 한계를 해결하고자 크게 두 방법을 제시한다.
1. 비대칭 encoder-decoder 구조
encoder의 경우 masked patches를 제외한 부분만 인코딩하게 되고,
decoder의 경우 인코딩된 부분과 masked 부분 모두에 대해 작동하게 된다.
따라서 decoder는 encoder에 비해 많은 연산을 하게 되므로 가벼운 구조를 갖게 된다.
2. 높은 masking 비율
language의 word에 비해 image의 pixel은 semantic 정보가 적다.
또한 image는 공간적 중복성이 높은 정보를 가져 보간법을 통해 픽셀 예측이 수월하다.
따라서 masking 비율을 75% 이상으로 하여 공간적 중복성을 제거하고자 하였다.
이를 통해 비교적 간단한 구조와 적은 자원으로 supervised learning보다 좋은 성능을 보였다.
다음은 MAE가 갖는 결과적 의미를 정리해보았다.
1) 연산량과 메모리 사용량 감소
encoder가 masking 영역을 제외하고 input 이미지의 25% 이하에 대해 연산, 가벼운 구조의 decoder의 사용
2) 큰 모델로의 확장성 용이
이미지의 적은 부분만을 이용하기에 큰 모델을 사용하여도 메모리 부담이 없음 ≫ generalize better!
0. Abstract
해당 논문에서는 MAE(Masked Autoencoder)가 CV에서 확장 가능한 self-supervisied learner임을 보임
Approach
입력 이미지에서 무작위로 patches를 mask한 후 해당 부분을 reconstruction하는 방향
Based Design
1) 비대칭 encoder-decoder 구조
encoder - mask 영역없이 visible 영역에 대해 작동
decoder - mask + encoded visible 영역 모두에 대해 작동
2) masking 비율을 높여 자명하고 의미있는 self-supervisory task 산출
≫ 2개의 based design을 합쳐 큰 모델을 효율적이고, 효과적으로 학습 가능
: 학습 속도 3배 이상 향상, accuracy 향상, 일반화 가능한 높은 수용성을 가진 모델 학습 가능
Performance
ViT-Huge model의 best accuracy 87.8%
Transfer 성능 (*downstream task)이 supervised pretraining 능가
1. Introduction
하드웨어의 급속한 발전
▷ 1. 100만 개의 이미지에 쉽게 과적합이 가능
2. 공개적으로 접근할 수 없는 수억 개의 labeled images 요구
이렇듯 많은 data 양에 대한 갈증을 NLP(natural language process) 분야에서 self-supervised pre-training에 의해 해결
≫data의 일부분을 지우고, 해당 부분을 예측하는 것을 학습하는 방안책!
1000억 개가 넘는 파라미터를 갖는 일반화 가능한 NLP 모델 학습 가능
(autoregressive language modeling in GPT + masked autoencoding in BERT)
CV 분야에서도 masked autoencoder 아이디어를 응용하는 연구에 대한 관심이 많아졌으나 (ex. BERT),
'language'와 'vision'의 차이에 의해 여전히 NLP 분야에 비해 CV 분야에서의 연구가 지연됨.
그렇다면 language와 vision에는 어떤 차이가 있을까?
1) 구조 (Architecture)
vision: convolution network는 정규 격자에 대해 동작되고,
mask tokens 또는 positional embeddings과 같은 지표를 통합하는 것이 단순하지 않음
≫ViT(vision transform)의 등장으로 구조적 차이 극복
2) 정보 밀도 (Information density)
vision: 이미지는 공간적 중복성을 가진 natural 신호
≫high-level 정보를 통해 이웃한 patches로부터 보간법을 통해 missing patches 추론 가능
그러나 low-level 정보 이상의 이미지의 전반적인 이해를 요하는 task의 경우 어려움이 있음
≫무작위로 많은 부분의 patches를 masking함으로써, 중복성을 줄이고 self-supervisory task 가능
language: 사람이 생성하는 매우 의미론적이고 정보 집약적인 신호
≫문장에서 약간의 missing word를 예측하고자하는 과정에서 세심한 언어 이해를 유도하게 됨
3) Decoder의 역할 (Role of decoder)
vision: pixel 단위의 복원이 이루어지므로 일반적으로 낮은 의미 관계(semantic level)를 가짐
≫따라서 decoder를 통해 잠재된 표현의 semantic level을 결정하게 되므로 decoder의 역할 중요!
language: 단어 단위의 복원이 이루어지므로 높은 의미 관계(semantic level)을 가짐
따라서 해당 논문에서는 Vision 학습을 위한 MAE 형태 제시
입력 이미지를 무작위로 patch 단위로 masking하여 pixel 공간 상에서 masking된 patches를 복원함
1. 비대칭 encoder-decoder 구조
2. 높은 masking 비율
encoder에서 전체 이미지의 25%에 대해서 encoding을 수행하고,
encoder에 비해 작은 scale의 decoder를 사용하여,
일부의 컴퓨팅 능력과 memory를 사용하여도 빠르게 pre-training 가능
뿐만 아니라 높은 수용성을 갖는 모델에 대해서 쉽게 확장 가능
≫fine-tuning ViT-H → accuracy 87.8%
3. Approach
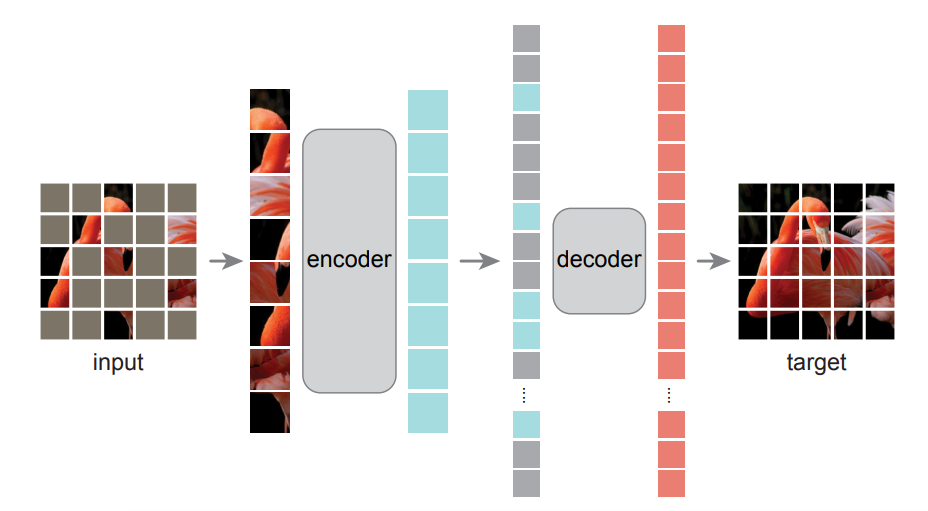
MAE는 autoencoder를 통해 손상되거나 노이즈가 심한 이미지로부터 원본 이미지로 복원하고자 하는 접근 방식으로,
고전적인 autoencoder와 다르게 비대칭 encoder-decoder 구조를 채택했다는 큰 차이점을 갖음.
Masking
Random sampling을 통해 masking할 영역을 정함.
Masking 영역의 비율이 큼 → input image의 75% 영역을 masking
MAE encoder
encoder: ViT
오직 visible patches(masking 하지 않은 patches)에 대해서만 encoding
MAE decoder
decoder: encoder에 비해 좁고, 얇은 scale을 가짐 → lightweight decoder
encoded visible patches + mask token 을 합쳐 decoding
pre-training 시에만 사용됨.
Reconstruction target
target: pixel value
loss function: MSE(Mean Square Error)
mask 영역의 pixel values를 예측하여 원본 이미지로 복원하고자 하기 때문에 target을 pixel value로 볼 수 있지만,
decoder의 output은 patches 당 pixel values의 vector 형태이므로 이를 이미지 형태로 reshape 해주어야 함.
≫ablation 연구로 patch 당 pixel value를 정규화하여 사용 → 성능 향상
loss의 경우 원본 이미지와 복원한 이미지 간의 차이를 계산하게 되며,
이미지의 모든 영역에 대해서가 아닌 masked 영역에 대해서만 계산함.
4. ImageNet Experiments
Baseline: ViT-Large를 backborn으로하여 fine-tuning
1. Self-supervised pre-training
training set: ImageNet-1K (IN1K)
2. Supervised training
a) end-to-end fine-tuning
b) linear probing
4-1. Main Properties
0) Default properties
masking ratio: 75%
decoder design: a) depth = 8
b) width = 512
mask token: not using
reconstruction target: unnormalized pixels
data augmentation: random resized cropping
mask sampling strategy: random sampling
training schedule: 800 epochs
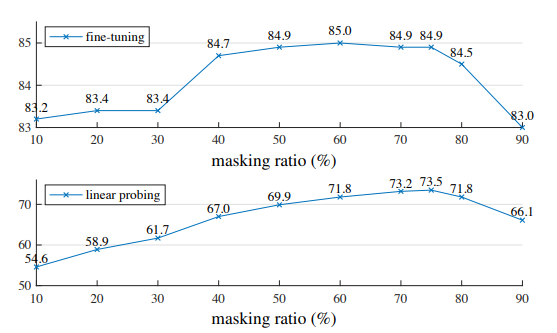
1) Masking ratio
masking ratio가 75%일 때 linear probing과 fine-tuning 결과 모두에서 좋은 성능을 보임
>linear probing - masking ratio가 증가함에 따라(최고점까지) accuracy도 점진적으로 증가
>fine-tuning - masking ratio에 덜 민감하여 넓은 범위(40~80%)에서 높은 accuracy를 보임
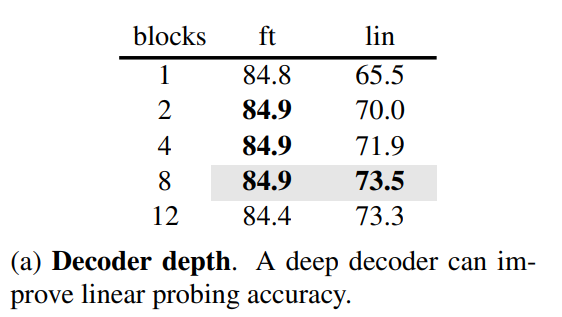
2) Decoder design
● Decoder depth (Transformer block 수)
decoder의 depth는 linear probing에 중요한 영향을 미침
마지막 layer 중 일부가 recognition보다 reconstruction에 특화되어 있음
그러나 fine-tuning에 사용할 경우 encoder의 해당 layers가 recognition task로 tuned되어 decoder의 depth 영향이 적음
>linear probing - depth를 증가함에 따라 accuracy가 향상 (8%의 향상)
>fine-tuning - single-block만으로도 큰 성능 향상을 보임
● Decoder width (Channels 수)
width는 default 값인 512-d일 때, fine-tuning 및 linear probing 모두에서 좋은 성능을 보임
width가 좁을 수록 fine-tuning 시 잘 작동
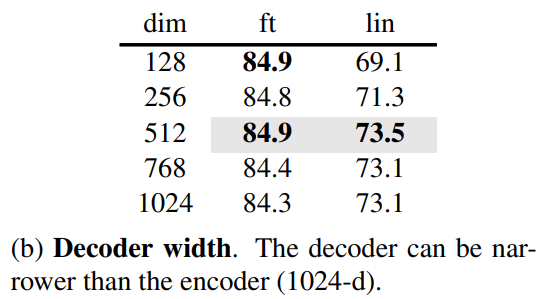
≫전반적으로 가벼운 decoder design으로 일부의 computing 능력으로 작업 수행 가능
3) Mask token
encoder에 mask token을 사용하지 않았을 경우,
real patches만을 보게 되면서 accuracy가 향상되고, 학습 시 연산량이 줄어듦.

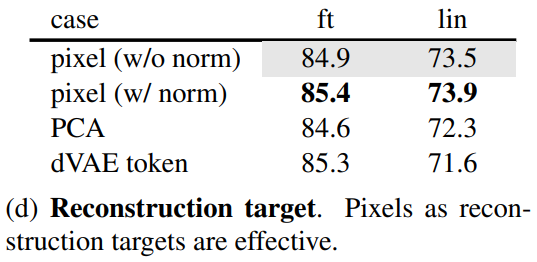
4) Reconstruction target
target을 정규화를 한 pixel, 정규화하지 않은 pixel, PCA, dVAE token으로 구성하여 비교하는 실험
정규화한 pixel을 target으로 한 경우 accuracy가 가장 높게 나옴.
5) Data augmentation
crop + random resize를 적용한 데이터 증강 시 가장 좋은 성능을 보임.
그러나 데이터 증강을 하지 않은 경우에도 낮은 성능을 보이지는 않는 것을 통해,
data augmentation에 의존도가 높은 *contrastive learning과 다르게 의존도가 낮음을 알 수 있음.
(random masking을 통해 데이터 증강과 관계없이 새로운 training 샘플 생성하기 때문)

6) Mask sampling strategy

mask 영역을 sampling하는 방법으로 block-wise, grid-wise, random sampling 비교하는 실험
block-wise의 경우 masking ratio가 50%일 때는 잘 되지만,
75%일 때 training loss가 증각하고 blur의 영향이 커지면서 성능이 저하됨.
grid-wise의 경우 쉽고, training loss가 낮고, sharp한 이미지로 복원이 되지만, representation quality가 낮음.
random sampling을 통한 masking이 가장 좋은 성능을 보임.

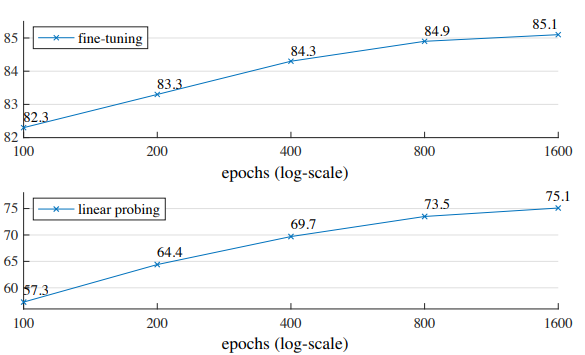
7) Training schedule
epoch를 늘릴 수록 accuracy가 점진적으로 증가하는 경향을 보임.
그러나 아무리 epoch를 높여도 linear probing accuracy의 saturation이 관찰 불가
contrastive learning의 경우 encoder는 200%의 patches를 보게되므로, 300 epochs만 가도 saturation 됨.
반대로 MAE의 경우 encoder가 매우 적은 25%의 patches를 보게되므로 saturation 관찰이 어려운 것이 아닐까 생각됨.
4-2. Comparisons with Previous Results
1. Self-supervised 방법과의 비교
self-supervised ViT 모델의 fine-tuning 결과 비교
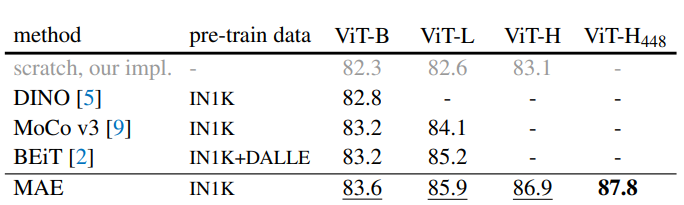
≫ViT-B 모델의 경우 모든 method에 대해서 비슷한 성능을 보였지만,
ViT-L과 같이 scale이 큰 모델의 경우 method마다 성능 차이가 크게 나타나는 것을 보임.
≫MAE가 다른 method에 비해 좋은 결과를 보임.
1) 쉽게 scale up 가능
다른 method에 비해 scale이 큰 모델을 사용할 수 있는 확장성이 good!
→ ViT-H (224 size)로 fine-tuning 시 86.9% accuracy
ViT-H (448 size)로 fine-tuning 시 87.8% accuracy
(IN1K data만을 사용한 method의 best accuracy 87.1% 능가)
→ 기본 모델인 ViT 기반에도 다음과 같이 좋은 성능을 보이므로, 더 좋은 network 활용 시 성능이 기대됨
2) 간단하고 빠르면서 높은 정확도를 냄
encoder에서 mask token을 사용하지 않고,
token을 predict하는 것이 아닌 pixel을 reconstruct하기에 dVAE pre-training이 필요하지 않음.
epoch를 1600처럼 크게 늘려도 동일한 하드웨어 조건에서 다른 method에 비해 총 pre-training 시간 소요 적음.
→ 빠른 학습 속도
2. Supervised pre-training과의 비교
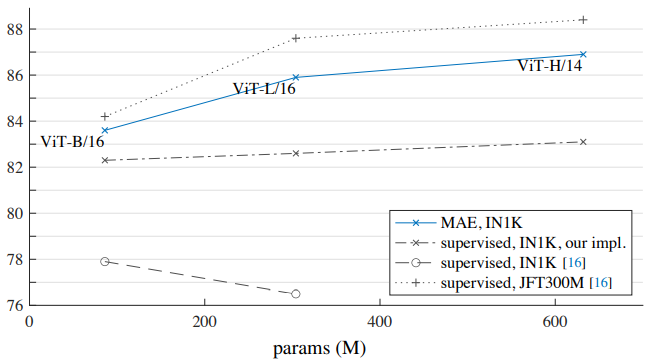
IN1K만을 사용 시, MAE이 supervised 학습 방법에 비해 더 일반화가 잘 되는 것을 보임.
→ ViT 논문에서 IN1K로 학습 시에 오히려 결과가 안 좋아지는 것을 확인
→ model의 scale을 높이는데 도움
또한, JFT300M으로 supervised pre-training한 결과와 비슷한 경향성을 보임.
4-3. Partial Fine-tuning
다른 모든 layers를 freezing한 상태로 마지막 몇 개의 layers에 대해서 fine-tuning 진행
▷Transformer block
Transformer block 1개에도 상당한 성능 향상을 보임. (73.5% → 81.0%)
적은 개수 (4 or 6)의 transformer blocks만을 사용하여 full fine-tuning에 가까운 accuracy 도달 가능.
▷MoCo v3와의 비교
Contrastive method인 MoCo v3의 경우, linear probing accuracy는 높지만 fine-tuning 결과는 MAE보다 떨어짐
≫MAE의 경우 비선형적 특징에 강하여 비선형 head가 tuning될 시 잘 됨
5. Transfer Learning Experiments
Object detection and segmentation
baseline: ViT Mask R-CNN
Semantic segmentation
baseline: UperNet
Classification task
iNat, Places로의 전이 학습
≫Object detection, Segmentation, Classification task에 대한 전이 학습 결과 모두 더 좋은 성능을 보임
Pixels vs token
dVAE tokens > unnomalizied pixels
dVAE tokens ≒ nomalizied pixels
≫tokenization의 성능이 정규화한 pixels에 대한 성능과 유사하므로,
tokenization이 필수적이지 않음
6. Discussion and Conclusion
딥러닝의 핵심은 확장성이 가능한 간단한 알고리즘임.
CV에서 실제적인 pre-training 패러다임은 self-supervised도 가능하지만 supervised가 주임.
해당 논문에서 제시한 MAE는
autoencoder를 통해 확장성을 갖는 self-supervised learner로의 이점을 제공하고,
복잡하고 전체적인 reconstruction 추론이 가능함!
Supplementation.
● Downstream task
pre-trained 모델을 통해 학습한 후, 원하는 작업을 위해 fine-tuning하여 모델을 업데이트 하는 방식의 작업에서
원하는 작업에 해당하는 부분을 downstream task로 볼 수 있음.
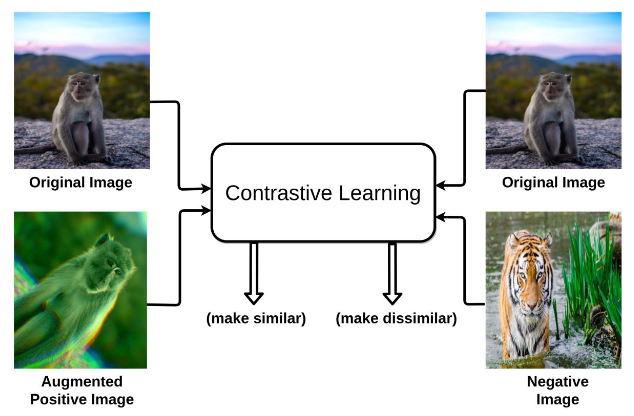
● Contrastive learning
입력 샘플 간의 비교를 통해 대상들의 차이를 좀 더 명확하게 보여줄 수 있도록 학습하는 방법으로,
표현 공간 상에 '비슷한' 데이터는 가깝게, '다른' 데이터는 멀게 존재하도록 학습하게 됨.
해당 논문에서 contrastive learning이 data augmentation에 의존적이라고 언급됨.
아래 사진과 같은 입력 샘플 쌍 생성 구조를 통해 데이터 증강에 의존적이라고 표현한게 아닐까 예상해 봄.
contrastive learning 시 입력 샘플의 쌍을 생성하기 위해 같은 이미지를 augmentation하여 positive pair을 만들고,
다른 이미지를 통해 negative pair를 만들게 되는 단계를 보여주는 것이 아래의 그림이라고 볼 수 있음.